Base pair

Depiction of the adenine-thymine Watson-Crick base pair.
A base pair (bp) is a unit consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, Watson-Crick base pairs (guanine-cytosine and adenine-thymine) allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence.[1] The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base pairing patterns that identify particular regulatory regions of genes.
Intramolecular base pairs can occur within single-stranded nucleic acids. This is particularly important in RNA molecules (e.g., transfer RNA), where Watson-Crick base pairs (guanine-cytosine and adenine-uracil) permit the formation of short double-stranded helices, and a wide variety of non-Watson-Crick interactions (e.g., G-U or A-A) allow RNAs to fold into a vast range of specific three-dimensional structures. In addition, base-pairing between transfer RNA (tRNA) and messenger RNA (mRNA) forms the basis for the molecular recognition events that result in the nucleotide sequence of mRNA becoming translated into the amino acid sequence of proteins via the genetic code.
The size of an individual gene or an organism's entire genome is often measured in base pairs because DNA is usually double-stranded. Hence, the number of total base pairs is equal to the number of nucleotides in one of the strands (with the exception of non-coding single-stranded regions of telomeres). The haploid human genome (23 chromosomes) is estimated to be about 3.2 billion bases long and to contain 20,000–25,000 distinct protein-coding genes.[2][3][4] A kilobase (kb) is a unit of measurement in molecular biology equal to 1000 base pairs of DNA or RNA.[5] The total amount of related DNA base pairs on Earth is estimated at 5.0 × 1037 and weighs 50 billion tonnes.[6] In comparison, the total mass of the biosphere has been estimated to be as much as 4 TtC (trillion tons of carbon).[7]
Contents
1 Hydrogen bonding and stability
1.1 Examples
2 Base analogs and intercalators
3 Unnatural base pair (UBP)
4 Length measurements
5 See also
6 References
7 Further reading
8 External links
Hydrogen bonding and stability
 |
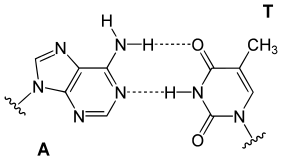 |
Hydrogen bonding is the chemical interaction that underlies the base-pairing rules described above. Appropriate geometrical correspondence of hydrogen bond donors and acceptors allows only the "right" pairs to form stably. DNA with high GC-content is more stable than DNA with low GC-content. But, contrary to popular belief, the hydrogen bonds do not stabilize the DNA significantly; stabilization is mainly due to stacking interactions.[8]
The larger nucleobases, adenine and guanine, are members of a class of double-ringed chemical structures called purines; the smaller nucleobases, cytosine and thymine (and uracil), are members of a class of single-ringed chemical structures called pyrimidines. Purines are complementary only with pyrimidines: pyrimidine-pyrimidine pairings are energetically unfavorable because the molecules are too far apart for hydrogen bonding to be established; purine-purine pairings are energetically unfavorable because the molecules are too close, leading to overlap repulsion. Purine-pyrimidine base pairing of AT or GC or UA (in RNA) results in proper duplex structure. The only other purine-pyrimidine pairings would be AC and GT and UG (in RNA); these pairings are mismatches because the patterns of hydrogen donors and acceptors do not correspond. The GU pairing, with two hydrogen bonds, does occur fairly often in RNA (see wobble base pair).
Paired DNA and RNA molecules are comparatively stable at room temperature, but the two nucleotide strands will separate above a melting point that is determined by the length of the molecules, the extent of mispairing (if any), and the GC content. Higher GC content results in higher melting temperatures; it is, therefore, unsurprising that the genomes of extremophile organisms such as Thermus thermophilus are particularly GC-rich. On the converse, regions of a genome that need to separate frequently — for example, the promoter regions for often-transcribed genes — are comparatively GC-poor (for example, see TATA box). GC content and melting temperature must also be taken into account when designing primers for PCR reactions.
Examples
The following DNA sequences illustrate pair double-stranded patterns. By convention, the top strand is written from the 5' end to the 3' end; thus, the bottom strand is written 3' to 5'.
- A base-paired DNA sequence:
ATCGATTGAGCTCTAGCGTAGCTAACTCGAGATCGC
- The corresponding RNA sequence, in which uracil is substituted for thymine in the RNA strand:
AUCGAUUGAGCUCUAGCGUAGCUAACUCGAGAUCGC
Base analogs and intercalators
Chemical analogs of nucleotides can take the place of proper nucleotides and establish non-canonical base-pairing, leading to errors (mostly point mutations) in DNA replication and DNA transcription. This is due to their isosteric chemistry. One common mutagenic base analog is 5-bromouracil, which resembles thymine but can base-pair to guanine in its enol form.
Other chemicals, known as DNA intercalators, fit into the gap between adjacent bases on a single strand and induce frameshift mutations by "masquerading" as a base, causing the DNA replication machinery to skip or insert additional nucleotides at the intercalated site. Most intercalators are large polyaromatic compounds and are known or suspected carcinogens. Examples include ethidium bromide and acridine.
Unnatural base pair (UBP)
An unnatural base pair (UBP) is a designed subunit (or nucleobase) of DNA which is created in a laboratory and does not occur in nature. DNA sequences have been described which use newly created nucleobases to form a third base pair, in addition to the two base pairs found in nature, A-T (adenine – thymine) and G-C (guanine – cytosine). A few research groups have been searching for a third base pair for DNA, including teams led by Steven A. Benner, Philippe Marliere, Floyd Romesberg and Ichiro Hirao.[9] Some new base pairs have been reported.[10][11][12]
In 1989 Steven Benner (then working at the Swiss Federal Institute of Technology in Zurich) and his team led with modified forms of cytosine and guanine into DNA molecules in vitro.[13] The nucleotides, which encoded RNA and proteins, were successfully replicated in vitro. Since then, Benner's team has been trying to engineer cells that can make foreign bases from scratch, obviating the need for a feedstock.[14]
In 2002, Ichiro Hirao's group in Japan developed an unnatural base pair between 2-amino-8-(2-thienyl)purine (s) and pyridine-2-one (y) that functions in transcription and translation, for the site-specific incorporation of non-standard amino acids into proteins.[15] In 2006, they created 7-(2-thienyl)imidazo[4,5-b]pyridine (Ds) and pyrrole-2-carbaldehyde (Pa) as a third base pair for replication and transcription.[16] Afterward, Ds and 4-[3-(6-aminohexanamido)-1-propynyl]-2-nitropyrrole (Px) was discovered as a high fidelity pair in PCR amplification.[17][18] In 2013, they applied the Ds-Px pair to DNA aptamer generation by in vitro selection (SELEX) and demonstrated the genetic alphabet expansion significantly augment DNA aptamer affinities to target proteins.[19]
In 2012, a group of American scientists led by Floyd Romesberg, a chemical biologist at the Scripps Research Institute in San Diego, California, published that his team designed an unnatural base pair (UBP).[20] The two new artificial nucleotides or Unnatural Base Pair (UBP) were named d5SICS and dNaM. More technically, these artificial nucleotides bearing hydrophobic nucleobases, feature two fused aromatic rings that form a (d5SICS–dNaM) complex or base pair in DNA.[14][21] His team designed a variety of in vitro or "test tube" templates containing the unnatural base pair and they confirmed that it was efficiently replicated with high fidelity in virtually all sequence contexts using the modern standard in vitro techniques, namely PCR amplification of DNA and PCR-based applications.[20] Their results show that for PCR and PCR-based applications, the d5SICS–dNaM unnatural base pair is functionally equivalent to a natural base pair, and when combined with the other two natural base pairs used by all organisms, A–T and G–C, they provide a fully functional and expanded six-letter "genetic alphabet".[21]
In 2014 the same team from the Scripps Research Institute reported that they synthesized a stretch of circular DNA known as a plasmid containing natural T-A and C-G base pairs along with the best-performing UBP Romesberg's laboratory had designed and inserted it into cells of the common bacterium E. coli that successfully replicated the unnatural base pairs through multiple generations.[9] The transfection did not hamper the growth of the E. coli cells and showed no sign of losing its unnatural base pairs to its natural DNA repair mechanisms. This is the first known example of a living organism passing along an expanded genetic code to subsequent generations.[21][22] Romesberg said he and his colleagues created 300 variants to refine the design of nucleotides that would be stable enough and would be replicated as easily as the natural ones when the cells divide. This was in part achieved by the addition of a supportive algal gene that expresses a nucleotide triphosphate transporter which efficiently imports the triphosphates of both d5SICSTP and dNaMTP into E. coli bacteria.[21] Then, the natural bacterial replication pathways use them to accurately replicate a plasmid containing d5SICS–dNaM. Other researchers were surprised that the bacteria replicated these human-made DNA subunits.[23]
The successful incorporation of a third base pair is a significant breakthrough toward the goal of greatly expanding the number of amino acids which can be encoded by DNA, from the existing 20 amino acids to a theoretically possible 172, thereby expanding the potential for living organisms to produce novel proteins.[9] The artificial strings of DNA do not encode for anything yet, but scientists speculate they could be designed to manufacture new proteins which could have industrial or pharmaceutical uses.[24] Experts said the synthetic DNA incorporating the unnatural base pair raises the possibility of life forms based on a different DNA code.[23][24]
Length measurements
The following abbreviations are commonly used to describe the length of a D/RNA molecule:
- bp = base pair(s)—one bp corresponds to approximately 3.4 Å (340 pm)[25] of length along the strand, and to roughly 618 or 643 daltons for DNA and RNA respectively.
- kb (= kbp) = kilo base pairs = 1,000 bp
- Mb (= Mbp) = mega base pairs = 1,000,000 bp
- Gb = giga base pairs = 1,000,000,000 bp.
For single-stranded DNA/RNA, units of nucleotides are used—abbreviated nt (or knt, Mnt, Gnt)—as they are not paired.
To distinguish between units of computer storage and bases, kbp, Mbp, Gbp, etc. may be used for base pairs.
The centimorgan is also often used to imply distance along a chromosome, but the number of base pairs it corresponds to varies widely. In the Human genome, the centimorgan is about 1 million base pairs.[26][27]
See also
- List of Y-DNA single-nucleotide polymorphisms
- Non-canonical base pairing
References
^ Zhurkin, Victor B; Tolstorukov, Michael Y; Xu, Fei; Colasanti, Andrew V; Olson, Wilma K (2005). Sequence-Dependent Variability of B-DNA. DNA Conformation and Transcription. pp. 18–34. doi:10.1007/0-387-29148-2_2. ISBN 978-0-387-25579-8..mw-parser-output cite.citation{font-style:inherit}.mw-parser-output q{quotes:"""""""'""'"}.mw-parser-output code.cs1-code{color:inherit;background:inherit;border:inherit;padding:inherit}.mw-parser-output .cs1-lock-free a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-limited a,.mw-parser-output .cs1-lock-registration a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-subscription a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration{color:#555}.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration span{border-bottom:1px dotted;cursor:help}.mw-parser-output .cs1-hidden-error{display:none;font-size:100%}.mw-parser-output .cs1-visible-error{font-size:100%}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-format{font-size:95%}.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-left{padding-left:0.2em}.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-right{padding-right:0.2em}
^ Moran, Laurence A. (2011-03-24). "The total size of the human genome is very likely to be ~3,200 Mb". Sandwalk.blogspot.com. Retrieved 2012-07-16.
^ "The finished length of the human genome is 2.86 Gb". Strategicgenomics.com. 2006-06-12. Retrieved 2012-07-16.
^ International Human Genome Sequencing Consortium (2004). "Finishing the euchromatic sequence of the human genome". Nature. 431 (7011): 931–45. Bibcode:2004Natur.431..931H. doi:10.1038/nature03001. PMID 15496913.
^ Cockburn, Andrew F.; Jane Newkirk, Mary; Firtel, Richard A. (1976). "Organization of the ribosomal RNA genes of dictyostelium discoideum: Mapping of the nontrascribed spacer regions". Cell. 9 (4): 605–613. doi:10.1016/0092-8674(76)90043-X.
^ Nuwer, Rachel (18 July 2015). "Counting All the DNA on Earth". The New York Times. New York: The New York Times Company. ISSN 0362-4331. Retrieved 2015-07-18.
^ "The Biosphere: Diversity of Life". Aspen Global Change Institute. Basalt, CO. Retrieved 2015-07-19.
^ Yakovchuk, Peter; Protozanova, Ekaterina; Frank-Kamenetskii, Maxim D. (2006-01-30). "Base-stacking and base-pairing contributions into thermal stability of the DNA double helix". Nucleic Acids Research. 34 (2): 564–574. doi:10.1093/nar/gkj454. PMC 1360284. PMID 16449200.
^ abc Fikes, Bradley J. (May 8, 2014). "Life engineered with expanded genetic code". San Diego Union Tribune. Archived from the original on 9 May 2014. Retrieved 8 May 2014.
^ Yang, Zunyi; et al. (August 15, 2011). "Amplification, Mutation, and Sequencing of a Six-Letter Synthetic Genetic System". J. Am. Chem. Soc. 133 (38): 15105–15112. doi:10.1021/ja204910n. PMC 3427765. PMID 21842904.
^ Yamashige, Rie; et al. (March 2012). "Highly specific unnatural base pair systems as a third base pair for PCR amplification". Nucleic Acids Res. 40 (6): 2793–2806. doi:10.1093/nar/gkr1068. PMC 3315302. PMID 22121213.
^ Malyashev, D. A.; et al. (July 24, 2012). "Efficient and sequence-independent replication of DNA containing a third base pair establishes a functional six-letter genetic alphabet". Proc. Natl. Acad. Sci. USA. 109 (30): 12005–12010. Bibcode:2012PNAS..10912005M. doi:10.1073/pnas.1205176109. PMC 3409741. PMID 22773812.
^ Switzer, Christopher; Moroney, Simon E.; Benner, Steven A. (1989). "Enzymatic incorporation of a new base pair into DNA and RNA". J. Am. Chem. Soc. 111 (21): 8322–8323. doi:10.1021/ja00203a067.
^ ab Callaway, Ewan (May 7, 2014). "Scientists Create First Living Organism With 'Artificial' DNA". Nature News. Huffington Post. Retrieved 8 May 2014.
^ Hirao, I.; et al. (2002). "An unnatural base pair for incorporating amino acid analogs into proteins". Nat. Biotechnol. 20 (2): 177–182. doi:10.1038/nbt0202-177. PMID 11821864.
^ Hirao, I.; et al. (2006). "An unnatural hydrophobic base pair system: site-specific incorporation of nucleotide analogs into DNA and RNA". Nat. Methods. 6 (9): 729–735. doi:10.1038/nmeth915. PMID 16929319.
^ Kimoto, M. et al. (2009) An unnatural base pair system for efficient PCR amplification and functionalization of DNA molecules. Nucleic acids Res. 37, e14
^ Yamashige, R.; et al. (2012). "Highly specific unnatural base pair systems as a third base pair for PCR amplification". Nucleic Acids Res. 40 (6): 2793–2806. doi:10.1093/nar/gkr1068. PMC 3315302. PMID 22121213.
^ Kimoto, M.; et al. (2013). "Generation of high-affinity DNA aptamers using an expanded genetic alphabet". Nat. Biotechnol. 31 (5): 453–457. doi:10.1038/nbt.2556. PMID 23563318.
^ ab Malyshev, Denis A.; Dhami, Kirandeep; Quach, Henry T.; Lavergne, Thomas; Ordoukhanian, Phillip (24 July 2012). "Efficient and sequence-independent replication of DNA containing a third base pair establishes a functional six-letter genetic alphabet". Proceedings of the National Academy of Sciences of the United States of America. 109 (30): 12005–12010. Bibcode:2012PNAS..10912005M. doi:10.1073/pnas.1205176109. PMC 3409741. PMID 22773812. Retrieved 2014-05-11.
^ abcd Malyshev, Denis A.; Dhami, Kirandeep; Lavergne, Thomas; Chen, Tingjian; Dai, Nan; Foster, Jeremy M.; Corrêa, Ivan R.; Romesberg, Floyd E. (May 7, 2014). "A semi-synthetic organism with an expanded genetic alphabet". Nature. 509 (7500): 385–8. Bibcode:2014Natur.509..385M. doi:10.1038/nature13314. PMC 4058825. PMID 24805238. Retrieved May 7, 2014.
^ Sample, Ian (May 7, 2014). "First life forms to pass on artificial DNA engineered by US scientists". The Guardian. Retrieved 8 May 2014.
^ ab "Scientists create first living organism containing artificial DNA". The Wall Street Journal. Fox News. May 8, 2014. Retrieved 8 May 2014.
^ ab Pollack, Andrew (May 7, 2014). "Scientists Add Letters to DNA's Alphabet, Raising Hope and Fear". New York Times. Retrieved 8 May 2014.
^ Alberts, Bruce; Johnson, Alexander; Lewis, Julian; Morgan, David; Raff, Martin; Roberts, Keith; Walter, Peter (December 2014). Molecular Biology of the Cell (6th ed.). New York/Abingdon: Garland Science, Taylor & Francis Group. p. 177. ISBN 978-0-8153-4432-2.
^ "NIH ORDR – Glossary – C". Rarediseases.info.nih.gov. Retrieved 2012-07-16.
^ Matthew P Scott; Paul Matsudaira; Harvey Lodish; James Darnell; Lawrence Zipursky; Chris A Kaiser; Arnold Berk; Monty Krieger (2004). Molecular Cell Biology (Fifth ed.). San Francisco: W. H. Freeman. p. 396. ISBN 978-0-7167-4366-8....in humans 1 centimorgan on average represents a distance of about 7.5x105 base pairs.
Further reading
Watson JD; Baker TA; Bell SP; Gann A; Levine M; Losick R (2004). Molecular Biology of the Gene (5th ed.). Pearson Benjamin Cummings: CSHL Press. (See esp. ch. 6 and 9)
Astrid Sigel; Helmut Sigel; Roland K. O. Sigel, eds. (2012). Interplay between Metal Ions and Nucleic Acids. Metal Ions in Life Sciences. 10. Springer. doi:10.1007/978-94-007-2172-2. ISBN 978-9-4007-2171-5.
Clever, Guido H.; Shionoya, Mitsuhiko (2012). "Chapter 10. Alternative DNA Base-Pairing through Metal Coordination". Interplay between Metal Ions and Nucleic Acids. Metal Ions in Life Sciences. 10. pp. 269–294. doi:10.1007/978-94-007-2172-2_10. ISBN 978-94-007-2171-5. PMID 22210343.
Megger, Dominik A.; Megger, Nicole; Mueller, Jens (2012). "Chapter 11. Metal-Mediated Base Pairs in Nucleic Acids with Purine and Pyrimidine-Derived Neucleosides". Interplay between Metal Ions and Nucleic Acids. Metal Ions in Life Sciences. 10. pp. 295–317. doi:10.1007/978-94-007-2172-2_11. ISBN 978-94-007-2171-5. PMID 22210344.
External links
| Wikimedia Commons has media related to Base pairing. |
DAN—webserver version of the EMBOSS tool for calculating melting temperatures
Genetics | |
|---|---|
| |
| Key components |
|
| Fields |
|
Archaeogenetics of |
|
| Related topics |
|
| |


